Executive Summary
Con la competizione tra provider di LLM che spinge i costi di inferenza verso prezzi commodity, le organizzazioni si trovano di fronte a una domanda strategica: dove risiede il valore duraturo in uno stack AI? Questo documento argomenta che il valore si concentra in due layer sopra il modello stesso: il Context, che rappresenta informazioni strutturate su utenti, organizzazioni e domini che rimangono portabili tra provider; e le Capabilities, che codificano l'expertise di dominio in formato eseguibile, indipendente da qualsiasi modello specifico.
L'architettura che presentiamo permette alle organizzazioni di produrre output specifici di dominio senza fine-tuning dei modelli né vendor lock-in, mantenendo la supervisione umana in ogni punto decisionale.
1. Problema
I Large Language Model funzionano come motori di ragionamento general-purpose capaci di elaborare input arbitrari e generare output coerenti in praticamente qualsiasi dominio. Questa generalità ha un costo: senza accesso a terminologia specifica del settore, standard di qualità e vincoli istituzionali, gli output dei modelli richiedono un'estesa revisione umana prima di poter essere applicati in contesti professionali. Quattro limitazioni strutturali spiegano perché.
Output generico
Un modello addestrato su dati pubblici non ha accesso alla terminologia della tua organizzazione, ai requisiti di compliance o ai criteri di qualità. Il gap tra output generico e output appropriato al dominio deve essere colmato manualmente, il che significa che ogni risposta richiede revisione rispetto a conoscenze istituzionali che esistono solo nella testa dei dipendenti o in documentazione sparsa.
Frammentazione del context
Le organizzazioni che usano più provider AI affrontano la frammentazione del context: istruzioni personalizzate, storico delle conversazioni e preferenze apprese rimangono siloed all'interno di ogni piattaforma. Un'organizzazione che costruisce context in ChatGPT perde quell'investimento quando valuta Claude, e lo perde di nuovo quando un nuovo provider entra nel mercato. Questo crea lock-in implicito senza commitment esplicito.
Expertise che non scala
La conoscenza di dominio tipicamente risiede nella testa di dipendenti senior che diventano colli di bottiglia man mano che l'adozione dell'AI aumenta la domanda del loro giudizio. Ogni decisione che richiede revisione da parte di un esperto resta in coda, e le persone junior del team non possono apprendere sistematicamente perché l'expertise si trasferisce solo attraverso interazione diretta con quegli stessi esperti sovraccarichi.
Delega senza giudizio
Gli attuali agenti AI possono eseguire task multi-step ma non possono valutare se gli output soddisfano gli standard organizzativi. Mancano dei criteri per la qualità che permetterebbero una delega genuina. L'esecuzione autonoma fa risparmiare tempo solo quando il sistema che esegue capisce cosa significa "fatto bene" nel tuo contesto specifico.
2. Soluzione
Questa architettura interpone due layer tra l'utente e l'LLM. Il layer Context memorizza informazioni strutturate su utenti, organizzazioni e domini in un formato che persiste tra le sessioni e si trasferisce tra provider. Il layer Capabilities codifica l'expertise di dominio come specifiche eseguibili che qualsiasi utente autorizzato può invocare, indipendentemente dal proprio livello di competenza.
Context
Utente, organizzazione, progetto, dominio
Capabilities
Knowledge, skill, tool
LLM
Layer di inferenza intercambiabile
Figura 1. Panoramica dell'architettura: layer Context e Capabilities sopra un LLM intercambiabile.
Poiché entrambi i layer sono definiti indipendentemente da qualsiasi modello specifico, le organizzazioni possono cambiare provider senza perdere il context accumulato o riscrivere le definizioni delle capability. L'LLM contribuisce la capacità di ragionamento; il Context contribuisce la rilevanza situazionale; le Capabilities contribuiscono l'expertise di dominio. Ogni layer può evolvere indipendentemente.
3. Context
Il layer Context mantiene informazioni strutturate che persistono tra le sessioni e si trasferiscono tra provider. Questo disaccoppiamento dal layer del modello significa che passare da Claude a GPT, o a qualsiasi provider futuro, non richiede di ricostruire la conoscenza organizzativa.
3.1 Layer di Dati
Il Context si organizza in quattro layer gerarchici. Il context Personale cattura ruolo, preferenze e stile di comunicazione. Il context Organizzazione memorizza informazioni aziendali, classificazione del settore, requisiti di compliance e linee guida del brand. Il context Progetto traccia obiettivi, vincoli, stakeholder e timeline. Il context Dominio contiene terminologia specializzata, best practice e requisiti normativi specifici del campo di lavoro.
Personale
Ruolo, preferenze, stile comunicativo
Organizzazione
Azienda, settore, compliance, brand
Progetto
Obiettivi, vincoli, stakeholder, timeline
Dominio
Terminologia, best practice, normative
Figura 2. I quattro layer gerarchici del context.
3.2 Principi di Design
Tre principi governano l'implementazione del Context:
- Ownership. Il context appartiene all'utente, non alla piattaforma, e può essere esportato in qualsiasi momento in formati standard.
- Portabilità. Il layer context opera indipendentemente da qualsiasi provider LLM specifico, così il context accumulato si trasferisce quando si cambia modello.
- Permesso. Il sistema non memorizza nulla senza approvazione esplicita dell'utente, e ogni elemento persistito richiede conferma.
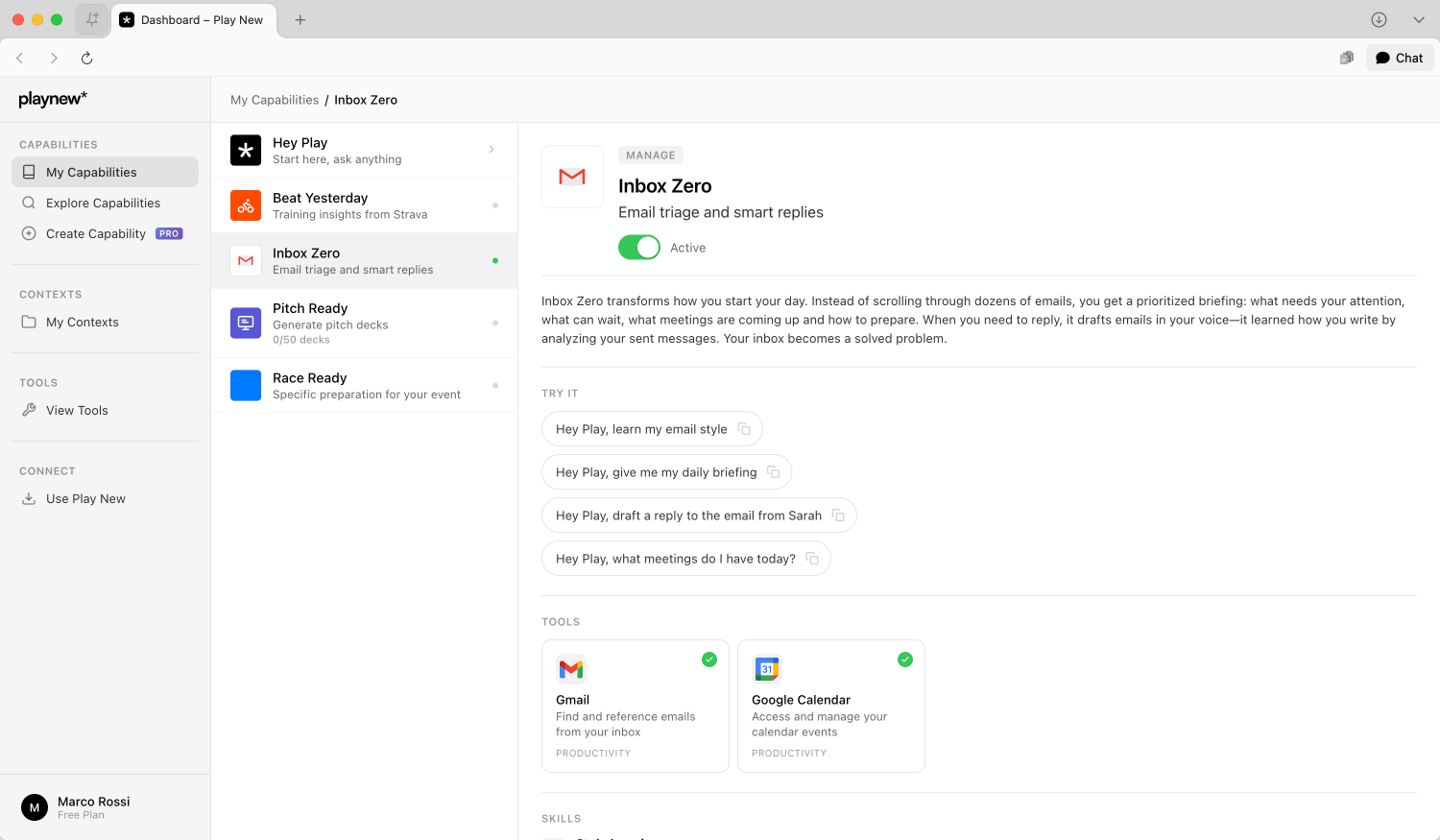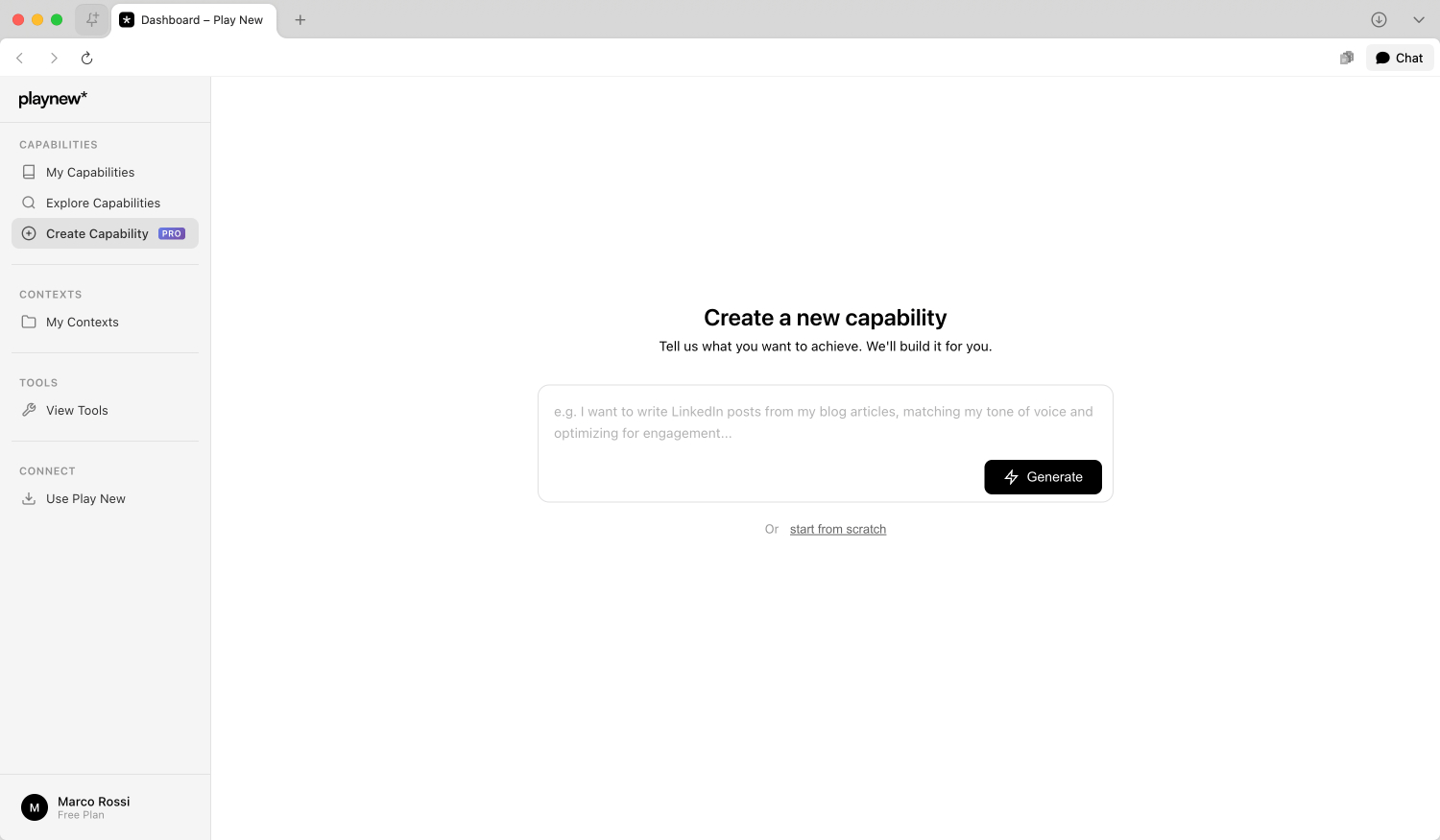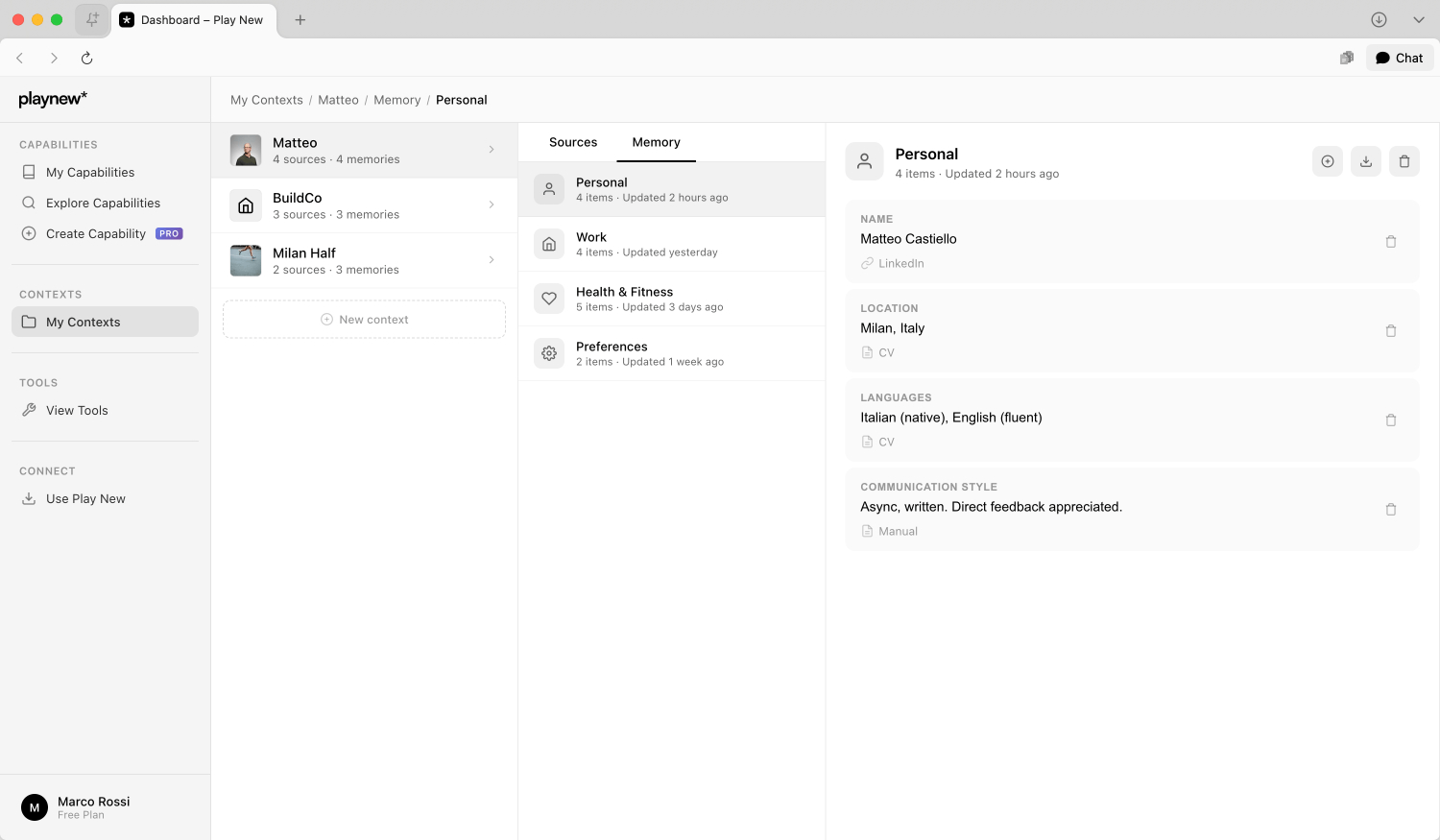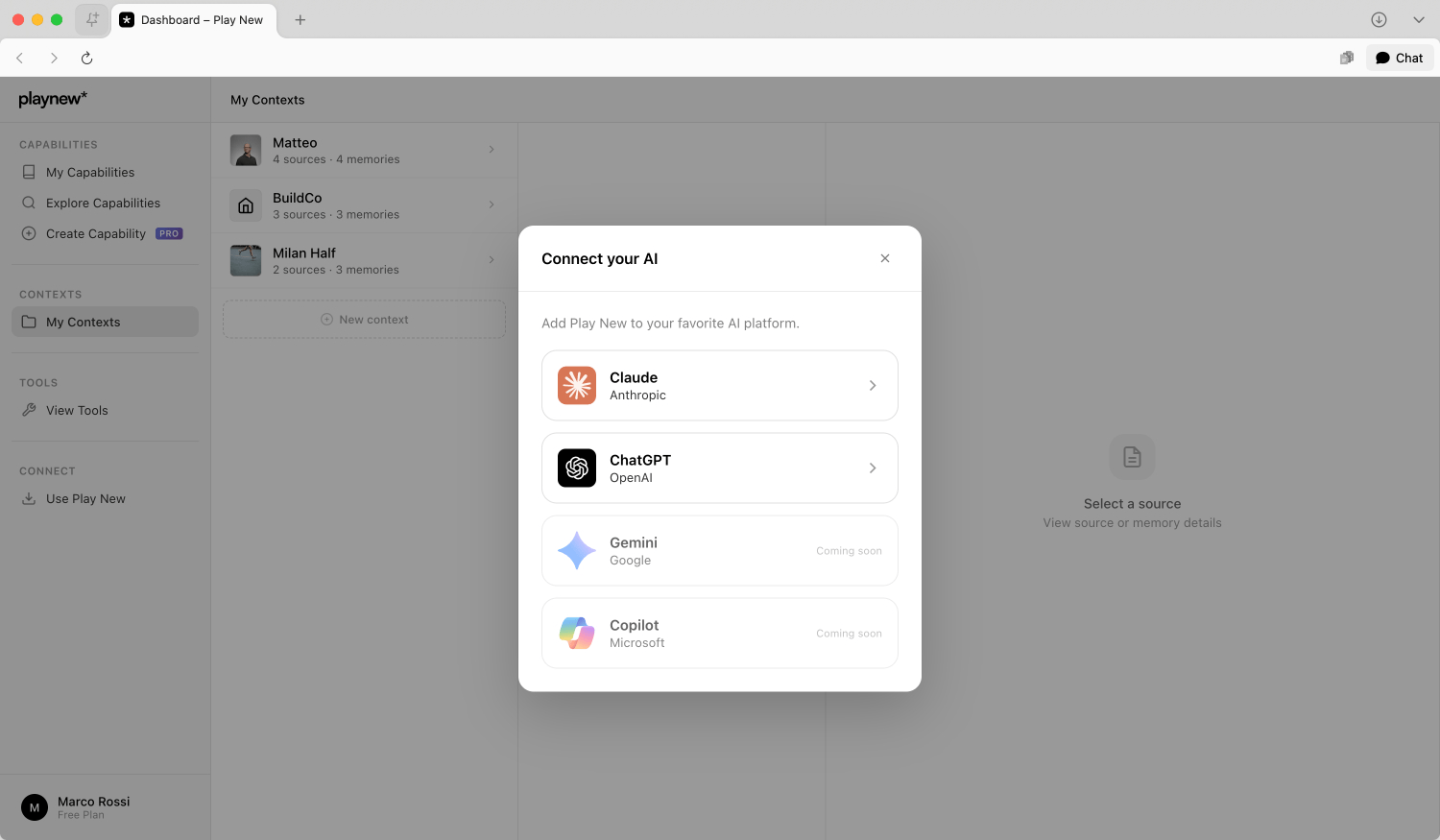
4. Capabilities
Una capability rappresenta expertise di dominio codificata in formato eseguibile. La conoscenza tacita che gli esperti faticano ad articolare diventa specifica esplicita che può essere documentata, versionata, trasferita tra team e scalata indipendentemente dagli esperti che l'hanno creata.
4.1 Componenti
Ogni capability combina tre elementi. La Knowledge contiene expertise di dominio indicizzata per il retrieval: regole decisionali, soglie, casi limite ed esempi annotati di output sia riusciti che falliti. Le Skill definiscono procedure con input, output e criteri di qualità specificati che determinano se gli output soddisfano gli standard. I Tool forniscono connessioni autenticate a servizi esterni che la capability potrebbe dover invocare durante l'esecuzione.
Knowledge
Regole decisionali, soglie, casi limite, esempi
Skill
Procedure, input, output, criteri di qualità
Tool
Connessioni autenticate a servizi esterni
Figura 3. I tre componenti di una capability.
4.2 Authoring
La creazione delle capability segue un workflow strutturato. Gli esperti definiscono knowledge, skill e connessioni ai tool attraverso un'interfaccia che non richiede programmazione. Prima del deployment, le capability vengono eseguite su input campione per verificare la qualità dell'output; gli autori confrontano i risultati con gli outcome attesi e raffinano le definizioni finché non soddisfano gli standard organizzativi. Le capability completate vengono distribuite all'interno dell'organizzazione con version control completo, permettendo rollback e audit di come ogni capability si è evoluta nel tempo.
5. Economia del Valore
La competizione tra i provider di LLM sta spingendo i costi di inferenza verso il basso, fino a renderli commodity. Quando ragionare costa poco, il valore duraturo si sposta su ciò che è difficile da copiare: il context che cresce con l'uso quotidiano e le capability che richiedono vera expertise di dominio. Questa architettura permette alle organizzazioni di trattenere quel valore, invece di cederlo a chi fornisce i modelli.
| Componente |
Ownership |
Valore |
| LLM |
Provider |
Commodity |
| Context |
Organizzazione + Individuo |
Duraturo |
| Capabilities |
Organizzazione + Individuo |
Duraturo |
Figura 4. Distribuzione del valore tra i layer dell'architettura.
6. Filosofia di Design
Dove il discorso attuale enfatizza gli agenti AI autonomi, questa architettura posiziona l'umano come agente. Il sistema fornisce leva per il processo decisionale umano invece di sostituirlo. Ogni processo inizia con una richiesta dell'utente e si conclude con la validazione dell'utente; il sistema amplifica la capability tra questi due momenti di giudizio umano ma non agisce indipendentemente.
Input
L'utente invia la richiesta
→
Elaborazione
L'LLM interpreta l'intento
Play New inietta context + capability
L'LLM genera la risposta
→
Output
L'utente rivede e decide
Figura 5. L'umano rimane l'agente durante tutto il workflow.
Da questa posizione derivano tre principi:
- Trasparenza. Ogni output è tracciabile alle sue fonti, e gli utenti possono ispezionare quale context è stato caricato, quale capability è stata invocata, e quale modello ha prodotto ogni risultato.
- Reversibilità. Nessuna azione diventa permanente senza conferma esplicita, e ogni operazione supporta l'undo.
- Auditabilità. Il sistema mantiene log completi di cosa è successo, quando e perché, supportando sia il debugging che i requisiti di compliance.
7. Per Iniziare
Le organizzazioni possono interagire con la piattaforma a tre livelli:
- Gli utenti iniziano sfogliando la libreria di capability per trovare expertise rilevante per il loro lavoro, installando capability e configurandole con il context organizzativo per adattare gli output a situazioni specifiche.
- Gli esperti di dominio che vogliono scalare la loro conoscenza usano l'interfaccia di authoring per codificare l'expertise come definizioni di capability, rendendo il loro giudizio disponibile ai colleghi che mancano di quel background specializzato.
- Gli amministratori distribuiscono le capability tra team o nell'intera organizzazione con audit trail e version control completi; la piattaforma supporta deployment sia cloud che on-premise a seconda dei requisiti di sicurezza.